
Overview and Methodology
The city of San Francisco depends on water from the Hetch Hetchy Reservoir which is filled from precipitation in the Tuolumne River watershed. I was interested in seeing what models of future climate thought about the effect of climate change on San Francisco’s water supply. Hetch Hetchy supplies 80% of the water for 2.6 million people1, so the effects of climate change could be quite significant.
In this post, I show how to use tools that we developed at Planet OS along with the data analysis tools in R to explore what climate models have to say about the future of the watershed.
The NASA OpenNEX project includes the DCP-30 dataset that is based on the CMIP-5 climate model runs designed facilitate comparison between various climate models created by institutions around the globe under a set of specified climate assumptions. DCP-30 contains data from 33 different models under 4 different scenarios picked to represent different options available to policymakers.2
Planet OS has developed an online tool to process the OpenNEX data into managable datasets to investigate specific cases. This tool is available at http://opennex.planetos.com.
In this case, we’ll use watershed information3 in conjunction with the Earth System Model/Modular Ocean Model from NOAA’s Geophysical Fluid Dynamics Laboratory (GFDL-ESM2M)4 to get a set of predictions on precipitation. We’ll compare model results for precipitation across all four scenarios.
The selection screen in Planet OS’s OpenNEX Access Interface looks like this:
The dataset selection for the data used here can be accessed at http://opennex.planetos.com/dcp30/i5End.
To instantiate the data construction tool and create a NetCDF file with the data used in this report, run the following script on a Linux or Mac system with Docker5 installed:
1
| |
This will generate a data.nc file in the current directory.6
Using R to Process the Model Data
We’ll use the R language to explore and understand the model data that we retrieved.7 I’ll show the R code that we’re using to process the data as we go along.
First, let’s load some important R libraries for this project and some constants that we’ll use later:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Results
To understand how precipitation varies over the region on average, let’s create a function that computes the average rainfall in each grid square in the DCP-30 data:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
To understand these averages, we’ll use the ggmap library to render them on a map:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
The model gives us a picture of distribution of precipitation across the watershed:
1
| |
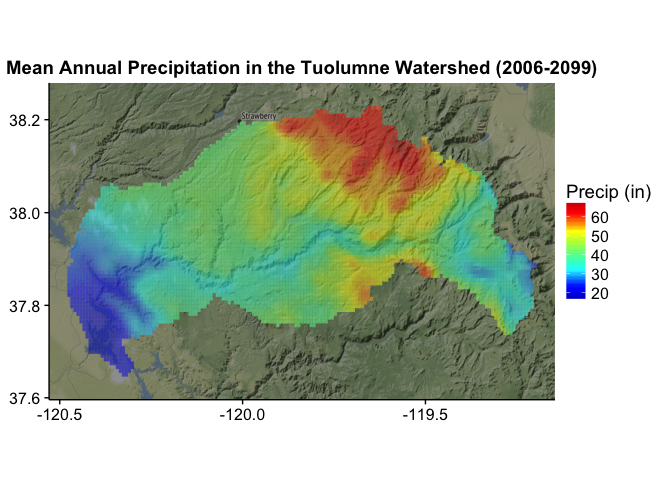
We can see how each of the scenarios changes over time. To do this, we view the mean precipitation (in inches8) for the overall watershed by year for each scenario.
First, we’ll compute the values:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
Now that we’ve computed the data and combined it into a single data frame, let’s take a look at it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
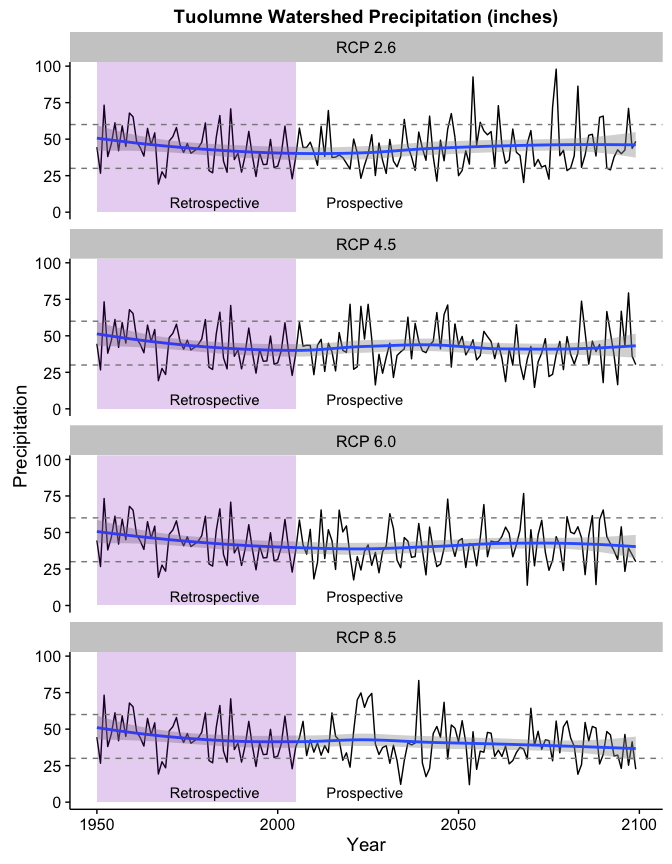
It looks here like the precipitation has a slight downward trend in the higher scenarios. Indeed, fitting a simple linear model shows a downward coefficient of 0.06 inches/year for the RCP 8.5 scenario.
The coefficients for each model are here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
| Scenario | Coefficient |
|---|---|
| RCP 2.6 | 0.01 |
| RCP 4.5 | -0.03 |
| RCP 6.0 | -0.03 |
| RCP 8.5 | -0.06 |
While the negative coefficients above aren’t that large, the model seems to understate the effect near the end if we look at the LOESS curve in the chart. Note also how the number of years below the 30" level (the lower dashed line) increase in the high carbon scenarios while the years above 60" (the upper dashed line) all but disappear towards the end of the century.
Charting the high and low precipitation years in each decade for each scenario lets us see this effect more clearly:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
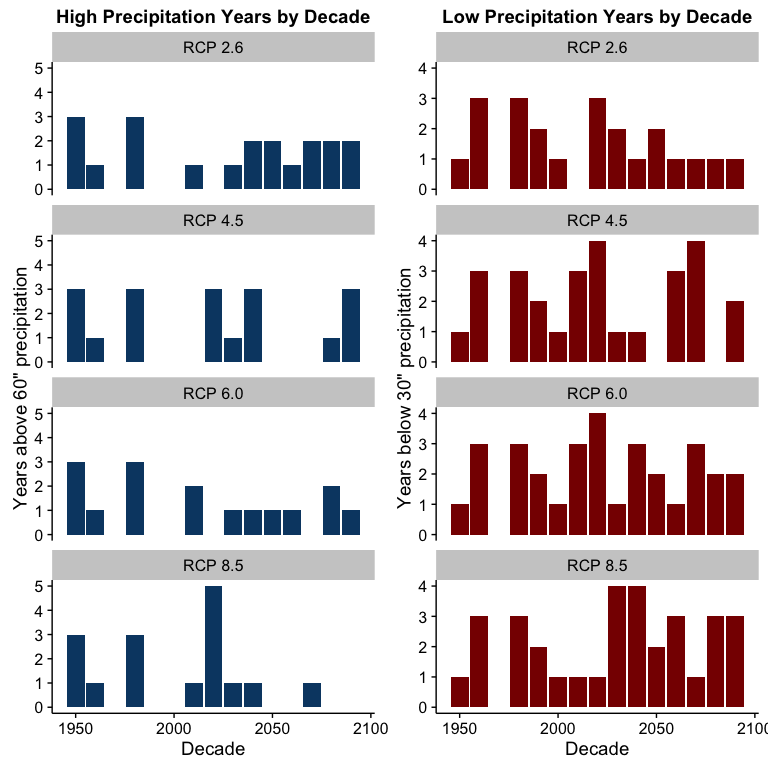
This chart would seem to indicate that higher atmospheric carbon levels are likely to be associated with increased drought risk and increased risk to the sufficient water supply in San Francisco.
A more detailed study would have to be done to quantify what the actual effect to the water levels in Hetch Hetchy might be, but these results indicate that that study might be justified.
-
https://en.wikipedia.org/wiki/Hetch_Hetchy#The_Hetch_Hetchy_Project↩
-
See a description of the 4 scenarios in “The representative concentration pathways: an overview” http://link.springer.com/article/10.1007/s10584-011-0148-z↩
-
The watershed definition is from the file
TUO_watersheds.kmldownloaded from UC Davis Center for Watershed Sciences http://hydra.ucdavis.edu/watershed/tuolumne↩ -
See http://www.gfdl.noaa.gov/earth-system-model for more information and access to source code for this model.↩
-
Docker is a containerization technology that lets you run programs without worrying about installing dependencies or effecting other parts of your system. You can learn more about installing it at http://www.docker.com.↩
-
The data access tool is still in pre-release and you’ll need special credentials to use it. Contact us for more details.↩
-
If you’re not familiar with R, it’s a language especially tailored for the statistical analysis of data. You can learn more about it here: https://www.r-project.org. I use RStudio, a free integrated environment for R that you can get here: https://www.rstudio.com.↩
-
Precipitation in the OpenNEX files is measured in $\frac{kg}{m^{2}s}$. We can use the fact that $1\text{kg}$ of water is $1000 \text{cm}^3$ to understand that this is $1 mm/s$ of accumulation. To convert to $inches/year$, we can use the following formula: $\frac{365\cdot86400\cdot0.1p}{2.54}$.↩